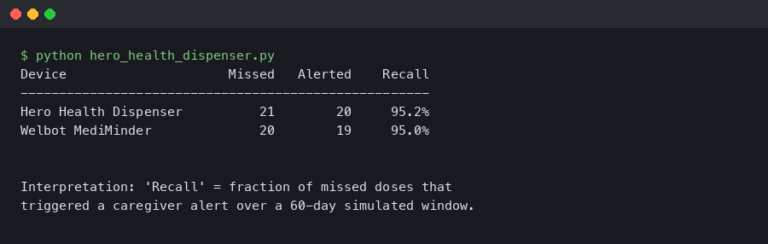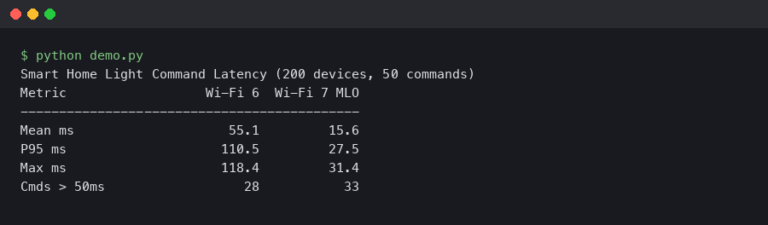

For decades, engineers and computer scientists have grappled with a challenge that the human brain solves effortlessly: the “cocktail party problem.” It’s the remarkable ability to focus on a single conversation amidst a cacophony of competing voices, clinking glasses, and background music. Replicating this feat computationally has been a monumental task in audio signal processing. Traditional methods often fell short, unable to cleanly disentangle the overlapping frequencies of multiple speakers from a single audio source. However, a new wave of artificial intelligence, powered by sophisticated deep learning models, is finally cracking this code. This breakthrough represents more than just an academic achievement; it’s a foundational technology poised to redefine our interaction with the digital world, marking a significant milestone in AI Audio / Speakers News and setting the stage for innovations across countless connected devices.
Understanding the Challenge: The Digital Cocktail Party
At its core, speaker separation, also known as source separation, is the process of isolating individual audio sources—specifically human voices—from a mixed, or monaural, recording. Imagine recording a meeting with three participants using a single microphone. The resulting audio file is a single waveform containing all three voices merged together. The goal of AI speaker separation is to take that one file and produce three separate, clean audio files, one for each participant. This is fundamentally different from noise cancellation, which focuses on removing non-human background sounds, or multi-channel recording, which avoids the problem altogether by using separate microphones for each source.
Why Is Speaker Separation So Difficult?
The difficulty lies in the physics of sound and the limitations of digital recording. When multiple people speak simultaneously, their sound waves combine in the air before reaching the microphone. This creates a complex, overlapping waveform where the frequencies of different speakers are intertwined. For a machine, distinguishing which parts of the signal belong to which person is an “underdetermined problem”—there is more source information than there are recording channels. Key challenges include:
- Frequency Overlap: The fundamental frequencies of human speech occupy a similar range, making it difficult to separate them using simple filters.
- Variable Amplitudes: Speakers may be at different distances from the microphone, speaking at different volumes, leading to one voice overpowering another.
- Acoustic Environment: Room reverberation and echoes cause sound to bounce and blend, further complicating the mixed signal.
- Non-Speech Sounds: Coughs, laughter, and background noises can be mistaken for parts of speech.
–
The AI Paradigm Shift in Audio Processing
Traditional signal processing techniques struggled with these variables because they relied on predefined mathematical assumptions about the audio signal. The paradigm shift came with the application of deep neural networks. Instead of being explicitly programmed with rules, these AI models are trained on vast datasets. They learn the intricate, statistical patterns that define an individual’s voice—timbre, pitch, cadence, and accent. By analyzing thousands of hours of mixed audio alongside the corresponding clean, isolated tracks, the AI learns to identify and reconstruct the individual sources from a novel mix. This data-driven approach, a cornerstone of modern AI Research / Prototypes, has proven far more robust and effective than any previous method, moving the technology from the lab into practical, real-world applications.
Inside the Black Box: The AI Techniques Driving Speaker Isolation
The magic of AI-powered speaker separation isn’t a single algorithm but a combination of sophisticated techniques that transform an audio challenge into a data-pattern recognition problem. The process typically begins by converting the raw audio waveform into a more structured format that a neural network can analyze effectively.
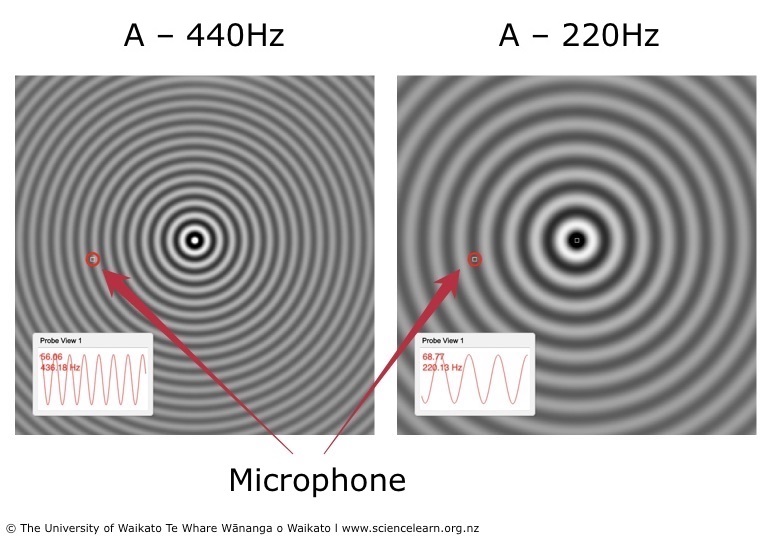
From Waveforms to Spectrograms: Visualizing Sound
Most modern AI audio models don’t work directly on the one-dimensional audio waveform. Instead, they convert it into a two-dimensional representation called a spectrogram. A spectrogram plots frequency against time, with the intensity of the color representing the amplitude (loudness) of a particular frequency at a specific moment. This effectively turns the audio problem into an image analysis problem, a domain where deep learning, particularly convolutional neural networks (CNNs), excels. This crossover of techniques is why advances in AI-enabled Cameras & Vision News often have parallel benefits in the audio space. The network learns to “see” the distinct patterns of different speakers within this visual representation of sound.
Key Deep Learning Architectures and Methods
Once the audio is represented as a spectrogram, the AI employs several architectures to perform the separation:
- Masking-Based Approaches: This is the most common and successful technique. The AI generates a “mask” for each identified speaker. This mask is essentially a filter, another spectrogram-like data structure that, when multiplied with the original mixed spectrogram, retains the information for one speaker while suppressing everything else. The model generates a unique mask for each voice in the mix, allowing for the reconstruction of separate, clean audio streams for each person.
- Time-Domain Models: While frequency-domain (spectrogram) models are popular, a newer class of models like Conv-TasNet operates directly on the raw audio waveform in the time domain. These models can sometimes avoid issues introduced during the conversion to and from the spectrogram format, potentially resulting in higher-fidelity audio output with fewer artifacts. This is a key area of development for on-device processing, relevant to AI Edge Devices News.
- Speaker-Conditioned Separation: The most advanced models go a step further. Instead of just separating all speakers, they can be “conditioned” to find a specific person. By providing the model with a short, 5-10 second clean sample of a target speaker’s voice, the AI uses that sample as a reference to generate a highly accurate mask for only that individual. This “speaker-aware” approach is incredibly powerful for applications where you need to isolate one known participant from a chaotic conversation.
The performance of these models is entirely dependent on the quality and quantity of their training data. They are trained on massive libraries of audio where both the mixed version and the perfectly isolated source tracks are available, allowing the network to learn the complex, non-linear function required to perform the separation.
From the Lab to Your Life: The Transformative Impact of Speaker Separation
The ability to computationally isolate voices is not just a technical novelty; it’s a foundational technology that unlocks a vast array of practical applications across consumer, enterprise, and creative sectors. This technology is rapidly becoming a key feature in the latest Smart Home AI News and beyond.
Enhancing Communication and Accessibility
In our daily lives, clear communication is paramount. AI speaker separation will make our interactions with technology more natural and effective. For example, AI Assistants News will feature devices that can distinguish a user’s command from the chatter of a television or other family members in the room. This greatly improves the reliability of voice commands in complex environments. For teleconferencing, a major focus of AI Office Devices, this technology can automatically generate a clean audio track for each meeting participant, leading to flawless transcriptions and intelligible recordings. Furthermore, the impact on accessibility is profound. For individuals with hearing loss, real-time speaker separation can power next-generation hearing aids or applications that isolate and amplify a specific speaker’s voice, a game-changer for AI for Accessibility Devices News.
Revolutionizing Media and Content Creation
For creative professionals, this technology is nothing short of revolutionary. In filmmaking and podcasting, it solves the age-old problem of “mic bleed,” where a microphone captures sound from unintended sources. An editor can now easily remove background chatter or isolate an actor’s dialogue from a noisy on-location shoot. This capability is a massive boon for AI Tools for Creators News. In music production, artists can now extract vocals or specific instruments from a mono or stereo master track for remixing, sampling, or remastering—a task that was previously considered nearly impossible. The technology also has serious applications in forensics and security, allowing analysts to clean up surveillance audio to better understand a conversation, a development relevant to AI Security Gadgets News and AI Monitoring Devices News.

The Future of Personal and Wearable Audio
The long-term vision extends to our personal devices. The latest Wearables News and Smart Glasses News point toward a future where our devices actively manage our auditory environment. Imagine smart earbuds that allow you to “mute” certain voices in a room or amplify the person you are looking at. This would be the ultimate real-time solution to the cocktail party problem, powered by efficient on-device processing. This technology will be integrated into everything from our phones, a key topic in AI Phone & Mobile Devices News, to the dashboards of our cars, influencing Autonomous Vehicles News by enabling clearer communication with in-car assistants.
Navigating the New Audio Landscape: Considerations and What’s Next
While AI-powered speaker separation is incredibly promising, it’s important to understand its current limitations and the best practices for leveraging it effectively. The technology is still evolving, and its performance can vary based on several factors.
Current Limitations and Pitfalls
- Audio Artifacts: The separation process is not always perfect. The resulting audio can sometimes contain digital artifacts, giving it a slightly “robotic” or “watery” quality, especially in very complex mixes with many speakers.
- Performance with Many Speakers: Most current models perform well with two or three speakers. As the number of simultaneous speakers increases, the accuracy of the separation tends to decrease significantly.
- Computational Cost: High-fidelity separation models are computationally intensive. While they run well on powerful cloud servers, achieving real-time performance on low-power hardware, like a smartphone or hearable device, remains a significant engineering challenge central to AI Edge Devices News.
–
Best Practices and Practical Tips
To get the best results from today’s speaker separation tools, users should keep a few things in mind. First, the principle of “garbage in, garbage out” applies. Starting with the highest quality, least compressed audio recording possible will always yield a better outcome. Second, whenever the option is available, use a speaker-conditioned model. Providing a clean reference sample of the target voice dramatically improves the AI’s ability to isolate that speaker accurately. Finally, for professional use cases, it’s often best to use AI separation as one step in a larger audio-cleaning workflow, combining it with traditional noise reduction and equalization tools to polish the final output.
The Road Ahead
The future of this technology is bright and points toward deeper integration with other AI systems. The next frontier is not just separating who is speaking, but also identifying them (speaker diarization) and transcribing what they are saying (speech-to-text) in one seamless process. As models become more efficient, we will see real-time speaker isolation become a standard feature in a wide range of products, from AI Personal Robots that can follow conversations to AI Kitchen Gadgets that can distinguish commands from different family members. This continuous innovation ensures that AI Audio / Speakers News will remain one of the most exciting fields to watch.
Conclusion: A New Era of Intelligent Audio
The ability to computationally unmix sound is a watershed moment in artificial intelligence and audio engineering. By solving the cocktail party problem, AI is not just improving existing applications but creating entirely new possibilities for how we interact with technology and each other. This breakthrough moves beyond simple voice commands to a more nuanced understanding of our complex, multi-layered auditory world. From enhancing accessibility and revolutionizing media production to paving the way for truly intelligent wearable devices, AI-powered speaker separation is a foundational technology that will resonate across nearly every sector. As the algorithms become more refined and efficient, the line between natural and digitally-mediated hearing will continue to blur, heralding a future where our technology doesn’t just listen, but truly understands.