
Stop Shouting at the Cloud
I have a rule in my house: if a smart device can’t function without an internet connection, it doesn’t belong in the wall. For years, this rule made my life difficult. I spent way too much time flashing custom firmware onto generic ESP32 chips just to get a light switch that didn’t need to ping a server in Virginia just to turn on a bulb in my kitchen.
But looking at the recent shifts in the semiconductor market, specifically the latest moves by companies like Knowles with their IA8201 architecture, I feel vindicated. The industry is finally admitting that sending every single voice command to the cloud is a terrible design philosophy.
We are seeing a massive pivot in **AI Audio / Speakers News** right now. The focus isn’t on the massive, power-hungry chips inside your phone anymore; it’s about the midrange. It’s about putting genuine neural network capabilities into the cheaper, smaller processors that live inside your thermostat, your washing machine, and your budget smart speaker.
This matters because it solves the two biggest problems plaguing voice interfaces today: latency and privacy. When I say “turn on the lights,” I want the lights on *now*, not two seconds later after a round-trip to a data center.
The Architecture of “Good Enough” AI
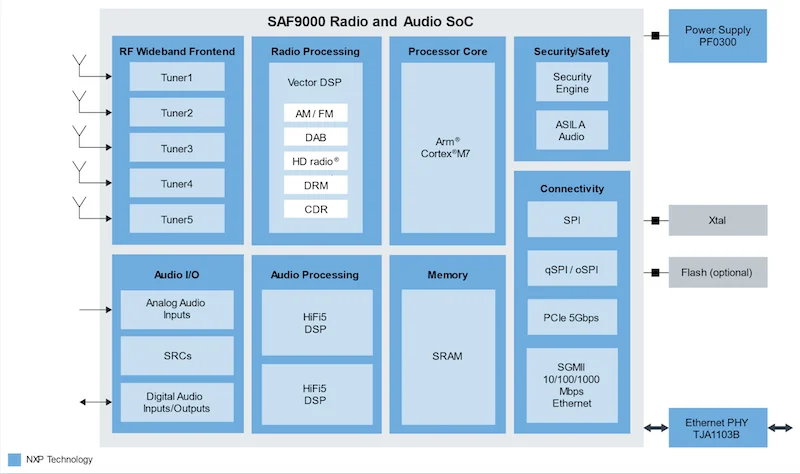
Let’s look at what’s actually happening under the hood. The buzz around the Knowles IA8201 update—adding AI capabilities to a midrange audio processor—is a perfect example of this trend.
Usually, when we talk about **AI Edge Devices News**, we talk about NPUs (Neural Processing Units) in high-end smartphones that cost $1,000. But you can’t put a Snapdragon processor in a $40 smart plug. It’s too expensive and generates too much heat.
The solution is what I call “micro-edge” processing. The IA8201 approach involves using multiple cores optimized for specific tasks. You have a standard DSP (Digital Signal Processor) that handles the heavy lifting of cleaning up the audio—removing the hum of your refrigerator or the sound of the TV in the background. Then, you have a separate core or instruction set specifically designed to run neural networks.
I find this fascinating because it separates “hearing” from “understanding.” The chip cleans the audio locally, and then runs a small, compressed neural network model right there on the silicon to detect specific keywords or acoustic events.
This isn’t ChatGPT running on your toaster. It’s a specialized model trained to recognize “Start Popcorn” or the sound of a glass breaking. Because it happens locally, the power consumption is measured in milliwatts, not watts.
Why the Midrange Market Controls the Future
I often argue that flagship tech is boring. Flagships can brute-force problems with raw power. The real engineering magic happens in the midrange, where constraints force creativity.
The update to the AISonic line is significant because it brings **Smart Home AI News** to devices that previously were just “dumb” terminals. Until recently, if a manufacturer wanted voice control in a coffee maker, they had two bad options: use a cheap, unreliable chip that only understood one word, or put in an expensive chip that destroyed their profit margin.
Now, with processors like the IA8201 supporting neural networks natively, we get a third option: affordable devices that actually work.
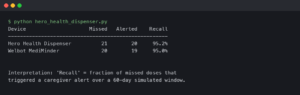
I’m seeing this impact **Smart Appliances News** heavily. I recently tested a microwave that uses local voice processing. It doesn’t have Wi-Fi. It doesn’t have an app. You just tell it “defrost 500 grams,” and it does it. It works instantly because the neural net is baked into the control board. This is the future I want—appliances that use AI to be better appliances, not to harvest my data.
The Privacy Implication
I can’t write about this without addressing the elephant in the room: privacy.
For years, **AI Security Gadgets News** has been dominated by stories of smart speakers recording things they shouldn’t. This happens largely because older, dumber chips were bad at wake-word detection. They relied on the cloud to verify if you actually said the magic word. That meant they were triggering constantly, sending snippets of your private conversations to a server for verification.
With the new generation of audio processors, the verification happens on the device. The neural network on the chip is smart enough to know the difference between “Alexa” and “Alex is here.”
If the chip determines you didn’t say the wake word, the audio data is discarded instantly. It never touches the radio. It never leaves the room. For me, this is the only way I’m comfortable having **AI Assistants News**-related hardware in my bedroom or office.
Battery Life and Wearables
The efficiency gains here are also reshaping **Wearables News**. I’ve been testing some of the newer true wireless earbuds that claim to have “context-aware” audio.
Previously, if you wanted earbuds to listen for a siren or a baby crying while you had noise cancellation on, the battery would tank. Constant listening requires constant processing.
But with these optimized audio processors, the “listening” requires almost zero power. The heavy-duty processing only wakes up when the low-power core identifies a specific acoustic signature.
I notice this difference in **AI Fitness Devices News** as well. Running watches that accept voice commands used to die halfway through a marathon if you left the feature on. Now, because the voice recognition is handled by a dedicated, low-power audio core rather than the main CPU, the battery impact is negligible.
The Developer’s Playground
From a development standpoint, this shift opens up some wild possibilities. I’ve been playing around with TensorFlow Lite for Microcontrollers recently, and the ability to deploy custom models to these DSPs is liberating.
It means we aren’t stuck with the keywords the manufacturer chose. In the **AI Tools for Creators News** space, I see a future where we can flash our own “hearable” models. Imagine a musician programming their amp to change settings based on a specific guitar riff, or a mechanic teaching their diagnostic tool to recognize the sound of a specific engine knock.
The barrier to entry is dropping. You don’t need a server farm to train these models anymore, and you don’t need a desktop PC to run them.
What This Means for 2026 and Beyond
As we look toward the next year, I expect the “dumb” speaker to go extinct.
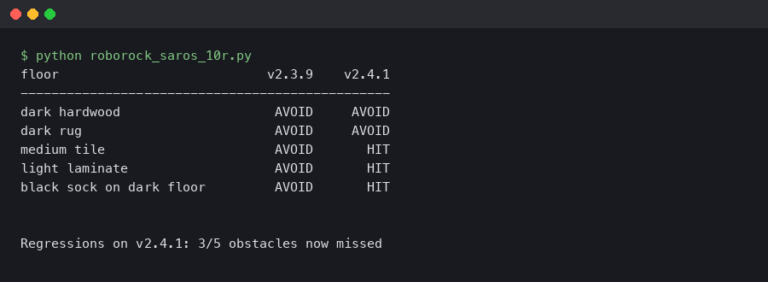
In **Robotics Vacuum News**, we are already seeing this. The new vacuums don’t just bump into things; they listen. If I drop a glass, the vacuum can hear the frequency of shattering glass and ask if I want it to come clean up. That requires a level of audio intelligence that simply wasn’t possible on a budget BOM (Bill of Materials) two years ago.
The same goes for **AI Pet Tech News**. I want a collar that tells me if my dog is barking in distress versus barking at a squirrel. That’s an audio classification problem. It requires a neural network. And now, the chips are cheap enough to put that tech on a dog collar.
The Fragmentation Challenge

However, I do have one concern. As every chip manufacturer rushes to add “AI” to their audio processors, we risk fragmentation.
If I’m building a smart home product, I have to decide which ecosystem to support. Does Knowles’ SDK play nice with my existing Matter implementation? Does the neural network support the specific wake word my brand uses?
I’ve run into issues where the hardware is capable, but the software stack is a nightmare. Integrating **AI Edge Devices News** tech into a cohesive product is still harder than it should be. We need better standardization in how these audio models are packaged and deployed.
The Reality of “Context”
The most exciting part of this progression isn’t just voice commands; it’s context awareness.
I recently read about developments in **AI Sensors & IoT News** where these audio processors are being used for presence detection. By analyzing the subtle changes in room acoustics (like ultrasound reflection), a smart speaker can know if someone is in the room without using a camera.
This is a game-changer for **AI Sleep / Wellness Gadgets News**. A device that monitors sleep breathing patterns using just audio processing—without sending a stream of audio to the cloud—is a privacy win and a utility win.
Final Thoughts
The addition of neural network capabilities to midrange chips like the IA8201 might seem like dry technical news. It’s just silicon, right?
But I see it as the moment where ambient computing actually becomes viable. We are moving away from the era of “Smart Speakers” that are actually just dumb conduits to the internet, and entering the era of “Intelligent Audio.”
I want my house to be smart even when the internet is down. I want my privacy respected by design, not by policy. And I want my battery-powered devices to last more than a day.
This shift in the semiconductor layer is what makes all of that possible. It’s not flashy, and it won’t make the front page of the mainstream news, but for those of us tracking **AI Audio / Speakers News**, it’s the most important development of the year.
The next time you talk to your appliances, pay attention to how fast they respond. If it’s instant, you probably have a chip like this to thank. If it lags, well, you’re probably still talking to a server in Virginia. And frankly, in 2025, that’s just not good enough anymore.