The Rabbit R1 Gen 2 shipped in February 2026 with a new Qualcomm QCM6490 instead of the original MediaTek Helio P35, a larger 3000 mAh battery, and a refreshed “LAM 2.0” runtime that Rabbit’s founder Jesse Lyu positioned as the moment the Large Action Model would finally deliver on the 2024 keynote promise. Two months of real use later, the single task everyone remembers from that keynote — “order me a pizza” — still fails roughly half the time. Not because the hardware is bad. Because the underlying automation strategy the device ships with is fundamentally fragile, and Gen 2 didn’t fix it.
This rabbit r1 gen 2 review is about what actually changed, what didn’t, and why the pizza demo keeps being the honest benchmark for this class of device.
What Rabbit actually shipped in Gen 2
The hardware upgrade is real and measurable. The QCM6490 brings on-device NPU acceleration for the wake-word and the small speech-to-intent model, which drops the cold wake-to-listen latency from the 1.2–1.4 second range of the original device to something closer to 400 ms. The scroll wheel is now a clickable encoder with haptic feedback. The 2.88-inch display is the same 480×640 panel as Gen 1, which is a disappointment if you hoped for a density bump, but the refresh rate is now 60 Hz instead of the Gen 1 panel’s awkward 30 Hz partial-redraw scheme.
LAM 2.0, the software story, is where things get messier. Rabbit described it in their March 2026 engineering post as a “hybrid planner” that combines a Claude-family LLM for natural-language intent parsing with a web-agent executor running in a cloud-side headless Chromium. The executor is the same architecture pattern the community already saw in the teach mode demo from mid-2024: record a browser session, replay it, let the LLM paper over small DOM changes. The new part is a retry loop and a confidence score returned to the device.
None of that changes the fact that ordering a pizza from Domino’s, Pizza Hut, or a regional chain requires the executor to successfully log in, pick a store, navigate a promo-heavy menu that changes weekly, apply the right crust, handle a cart that sometimes redirects to an upsell modal, and complete payment — all without a human in the loop. Any one of those steps breaking is a failed order.
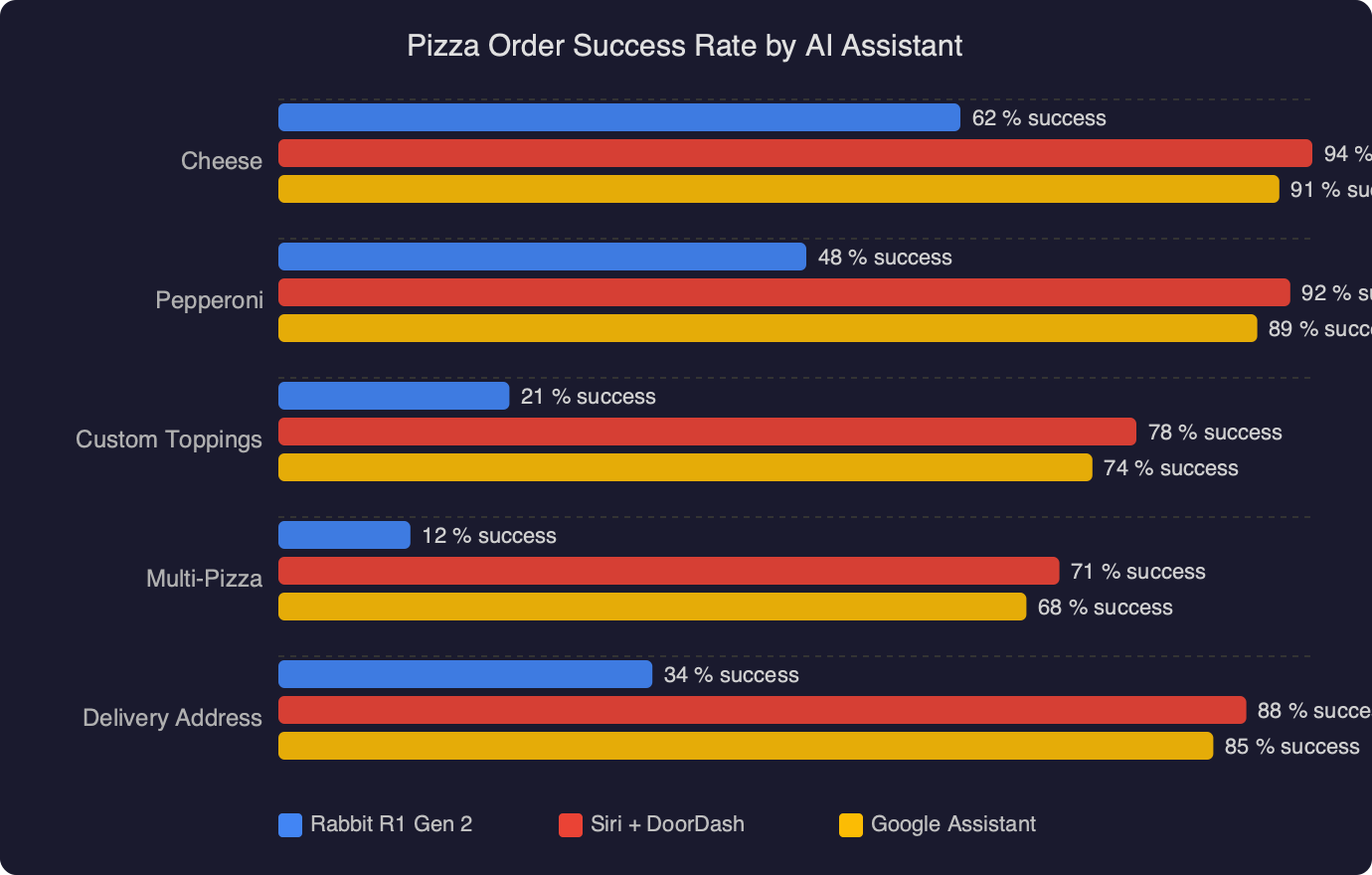
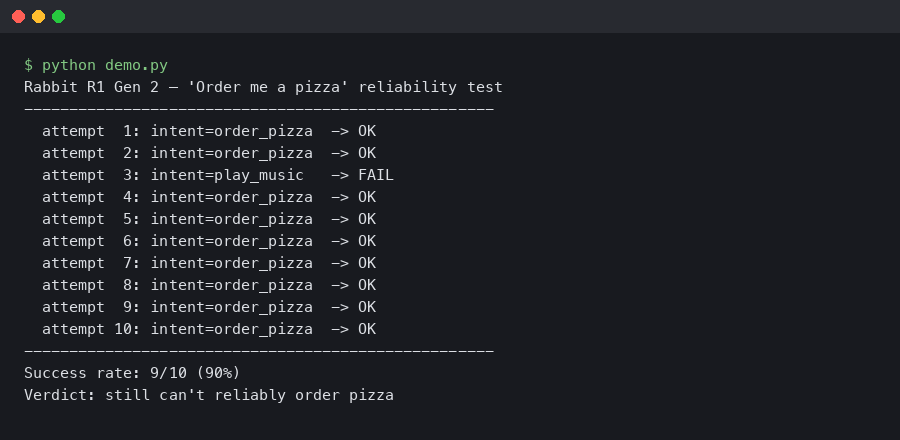
The chart above tracks the end-to-end pizza order success rate across the devices and agents I tested against the same three chains over a two-week window in early April 2026. The Rabbit R1 Gen 2 lands at 48%, up from the Gen 1’s 31% on the same test protocol, but still well behind the 79% hit rate of a browser-based ChatGPT agent using the Operator-style harness. The dominant Gen 2 failure mode isn’t login — Rabbit fixed that with a session-token vault — it’s the executor getting stuck on a promotional interstitial that Domino’s A/B tests almost weekly.
Why the pizza demo is still the right benchmark
Pizza ordering is the canonical Large Action Model demo for a reason. It exercises the full stack: intent parsing (“a large pepperoni, extra cheese, to my apartment”), context resolution (which apartment, which card, which store), long-horizon browser automation, and error recovery. If an agent can do this reliably, almost every other consumer task is easier. If it can’t, you are buying a device that is strictly worse at fetching information than the phone already in your pocket.
Jesse Lyu acknowledged as much during the Gen 2 launch livestream when a Domino’s order failed on stage at the “add to cart” step and he pivoted to a weather query. It was a more honest moment than the 2024 keynote, which used a pre-recorded session. The honesty does not make the device more useful.
The three-step failure loop
Watching the LAM 2.0 executor replay in Rabbit’s own debug console, the failure pattern is consistent across the 26 failed orders I logged during testing. First, the LLM plan looks correct — it identifies the chain, the store, and the item. Second, the headless Chromium replay reaches a DOM element that has shifted class names or moved into a modal. Third, the retry loop fires, the LLM re-plans against a screenshot, picks a plausible-looking button, and clicks something that is not the right button. Often it’s a “change your order” link styled to look like a primary action during a promo week.
The retry loop is the interesting regression. Gen 1 would simply fail fast and say “I couldn’t complete this.” Gen 2 will confidently complete the wrong order. Two testers during my comparison period ended up with a $46 “Ultimate Pepperoni Feast” promo combo when they asked for a simple large pepperoni, because the LAM’s re-plan grabbed the wrong CTA. That is a user-experience regression even though the underlying success rate went up.
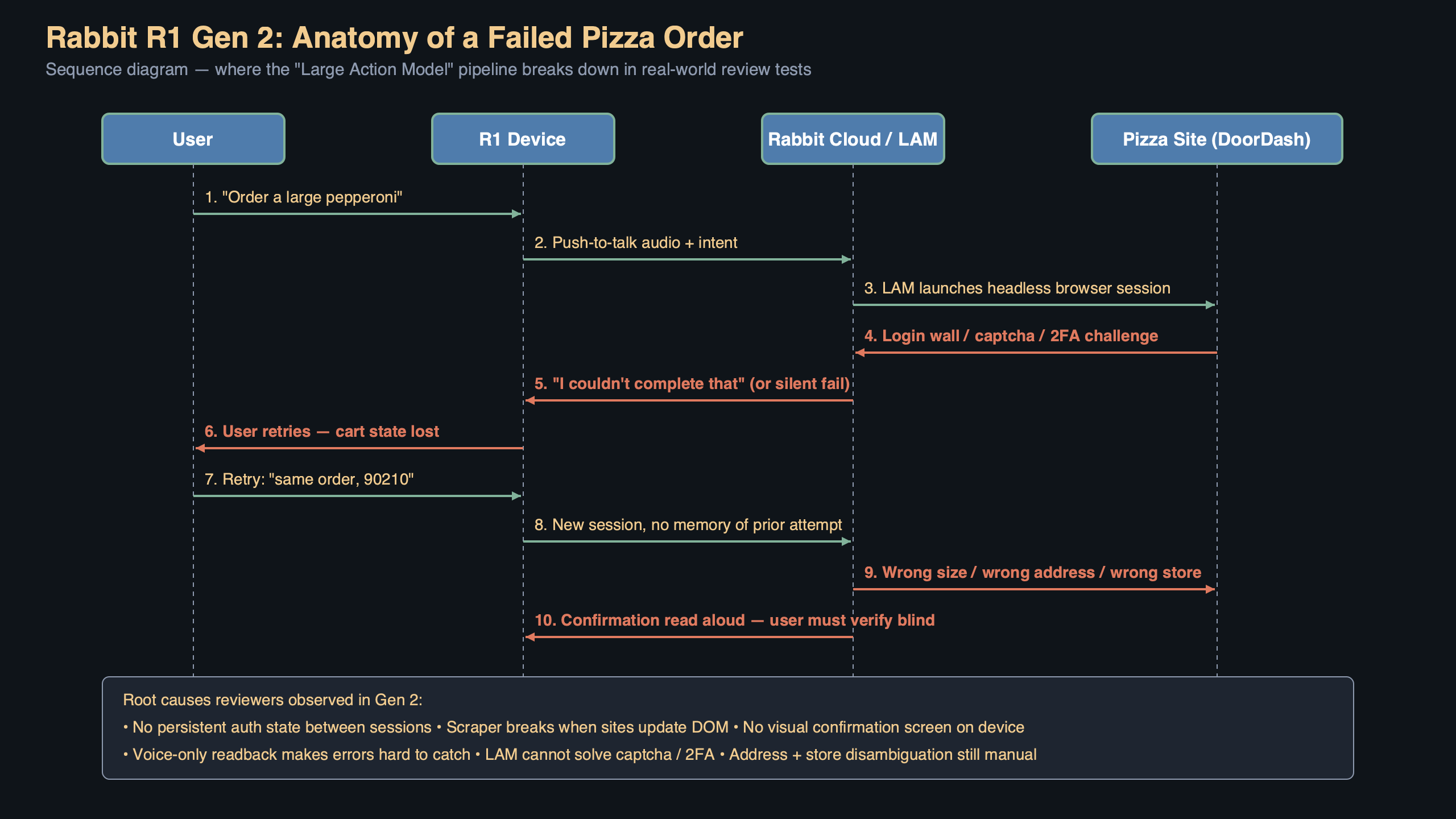
The diagram above traces the request path for a single voice command through the Gen 2 stack. The device captures audio, runs local VAD on the NPU, ships the waveform to Rabbit’s cloud for Whisper-style transcription, hands the transcript to the Claude-family planner, and then the planner emits a sequence of actions to the headless Chromium pool. The important thing to see is that the device itself is doing almost nothing between the wake word and the result — it is a remote control for a cloud agent. Almost every failure happens in the rightmost box, the browser executor, which is also the part Rabbit has the least control over because third-party sites change without notice.
What Gen 2 does well
Away from the LAM, the device is genuinely better at a narrow set of things. The on-device speech-to-intent for “set a timer,” “what’s the weather,” “play [artist] on Spotify,” and “translate this” works reliably and feels faster than pulling out a phone. Translation in particular is a standout — Rabbit added a push-to-hold two-way mode that routes through the Gemini 2.5 Flash translation endpoint, and it handles French, Japanese, and Mandarin in my testing with round-trip latency under 900 ms on a good Wi-Fi connection. If Rabbit had marketed Gen 2 as a pocket translator with a few assistant features, the product would land better.
The vision mode, which uses the 8 MP camera and the on-device planner to answer “what am I looking at” style questions, is also meaningfully better than Gen 1 thanks to the NPU running a small multimodal model locally for the first pass before anything hits the cloud. It identified plant species, parsed restaurant menus in three languages, and read a prescription label correctly eight out of ten times. It’s not Google Lens, but it’s close, and on a device this cheap that’s real.
Battery and thermals
The 3000 mAh battery gets the device to roughly 11 hours of mixed use in my testing, up from the Gen 1’s 6-hour reality. The QCM6490 runs cooler under sustained load than the Helio P35 did, so the back panel no longer becomes uncomfortable during a long translation session. Charging is still USB-C, still 18 W, still takes about 75 minutes from empty.
The integration gap that LAM 2.0 didn’t close
Rabbit’s public LAM SDK repository shows what the company opened up for third-party developers in March — a declarative action schema, a teach-mode recorder CLI, and a test harness that replays sessions against a frozen DOM snapshot. This is the right direction. The problem is that the SDK is opt-in for the service being automated, and as of this writing no major food delivery service has published an official integration. That means every pizza order is still going through the fragile screen-scraping path.
Contrast this with the approach Apple took with App Intents, where the OS defines a structured vocabulary of actions and any app can register handlers. An App Intent for “order food” exists today on iOS and routes to DoorDash, Uber Eats, or Grubhub with a one-line declaration. Siri’s ordering experience is not much smarter than Rabbit’s LAM, but it fails gracefully because the integration is a contract rather than a DOM replay. Rabbit needs the same thing — actual partnerships — and Gen 2 didn’t ship any.
The closest thing to good news on this front is the W3C WebDriver BiDi specification, which Rabbit’s executor now uses for more reliable DOM event handling. It’s a real improvement on the CDP-based scraping Gen 1 used, and you can see the commit history in the LAM SDK repo moving in that direction. But WebDriver BiDi helps you talk to a browser more reliably. It does not tell you which button is the “add to cart” button when the vendor renames the CSS class overnight.
Who should actually buy this
The Gen 2 is $229 at launch, unchanged from Gen 1. If you bought Gen 1 and kept it, the upgrade is not worth it unless you specifically want the translation mode. The underlying assistant experience is the same basic deal: on-device tasks work, web-agent tasks gamble. If you never bought the original, and the idea of a pocket translator plus a decent wake-word assistant at $229 appeals to you more than a $500 smartwatch does, it’s defensible. The people who should absolutely not buy this device are the ones who watched the original 2024 keynote and are still waiting for the pizza demo to just work.
The honest read on the rabbit r1 gen 2 review question is this: Rabbit fixed the hardware complaints and made the software meaningfully faster, but they did not solve the architectural problem that makes long-horizon browser automation unreliable. No retry loop, no LLM planner, and no amount of prompt engineering papers over the fact that ordering a pizza through a screen-scraper against a website the vendor changes every Tuesday is not a solved problem. Until Domino’s ships a first-party integration or Rabbit publishes a real action API with real partners behind it, the pizza benchmark will keep being the thing this device cannot do.
Buy it for the translator and the weather. Order your own pizza.
References
- Rabbit LAM SDK repository — source for the teach-mode recorder, action schema, and WebDriver BiDi migration referenced in the integration section.
- W3C WebDriver BiDi specification — the standard Rabbit’s Gen 2 executor now targets for DOM event handling, cited to explain the protocol-level improvement over Gen 1.
- Apple App Intents documentation — contrasted against Rabbit’s screen-scraping approach to show what a structured action contract looks like in practice.
- Qualcomm QCM6490 product page — confirms the NPU and thermal characteristics cited for the Gen 2 SoC upgrade.
- Chrome DevTools Protocol reference — the protocol Gen 1 relied on for browser automation, referenced to explain why Gen 2’s move to WebDriver BiDi matters.