
On device wake word chips are ultra-low-power audio front ends, DSPs, MCUs, or NPUs that listen for a phrase locally, keep a short rolling buffer, and wake the main processor only when a keyword model crosses a confidence threshold. The caveat is simple: “local wake word” does not automatically mean “no audio risk.” Privacy depends on where the buffer lives, when networking starts, and whether the LED or mute switch follows the real capture hardware.
Overview
- What an on-device wake-word chip actually does
- The always-on path: mic, DMA buffer, DSP features, NPU score, host interrupt
- Why the rolling buffer is the hidden privacy boundary
- DSP, MCU, NPU, or server: the architecture choice that decides battery life
- Privacy LEDs and mute switches: the trust signal has to follow the hardware state
- How to read power claims without being misled
- A reviewer checklist for real devices
- References
- Related reading
- Sensory describes embedded wake-word models for constrained devices, with small memory footprints that can fit low-resource consumer hardware.
- Syntiant’s NDP-family wake-word chips are positioned around always-on neural inference at very low component power, before counting microphones, memory, host wakeups, or radio use.
- Home Assistant separates server-side openWakeWord from microWakeWord on ESP32-S3-class devices, a useful distinction for buyers comparing “local” claims.
- A local wake phrase often only gates activation; many assistants still stream the command after the wake event.
- The strongest privacy design has a hardware mute path and an indicator tied to microphone power or capture state, not only app software.
What an on-device wake-word chip actually does
An on-device wake-word chip is a power-gated audio pipeline, not a privacy label by itself. Its job is to keep a tiny part of the device awake, turn live microphone samples into compact features, score those features against a keyword model, and interrupt the larger system only when the phrase looks likely enough. That design saves battery and reduces network exposure, but it does not remove every audio boundary.
In a smart speaker, camera, thermostat, TV remote, pair of earbuds, robot vacuum, or smart glasses, the expensive parts are usually asleep during idle. The application processor, Wi-Fi radio, Bluetooth stack, screen, and cloud assistant session cost far more energy than a small always-listening front end. Wake-word silicon exists so those parts do not wake on every syllable in the room.
The phrase “on-device” should be read as a chain-of-custody claim: which part samples the microphone, which memory stores recent audio, which processor runs inference, which event wakes the host, and which policy decides whether audio leaves the home. A vendor can truthfully say the wake word is detected locally while still sending the spoken command to a cloud assistant after activation.
That distinction matters for AI Assistants News readers because consumer devices collapse several states into one phrase: “always listening.” A device may be always sampling but not storing. It may store a one- or two-second ring buffer but not upload it. It may wake locally and then stream only after the trigger. Or it may do server-side wake detection, where the privacy and bandwidth story is completely different.
Three product families show the spread. Sensory’s TrulyHandsfree wake-word technology describes embedded speech recognition for low-resource devices and cites compact memory footprints for constrained chips. Syntiant’s Neural Decision Processor architecture is built around always-on neural inference at very low power. Home Assistant’s voice stack documents both openWakeWord and microWakeWord, showing that “local” can mean a server on the LAN or a model running on the satellite device itself.
The buyer-facing question is not “does it have AI?” It is: when the room is quiet, what silicon is awake; when someone says the wake phrase, what buffer is replayed; and after the device wakes, what leaves over the network?
The always-on path: mic, DMA buffer, DSP features, NPU score, host interrupt
The always-on path usually starts with PDM microphone audio, moves through a DMA ring buffer, converts speech into MFCC or log-mel features, scores those features with a keyword model, and raises an interrupt line to the host when confidence passes a threshold. Each step changes the privacy and battery profile because audio, features, and control signals live in different places.
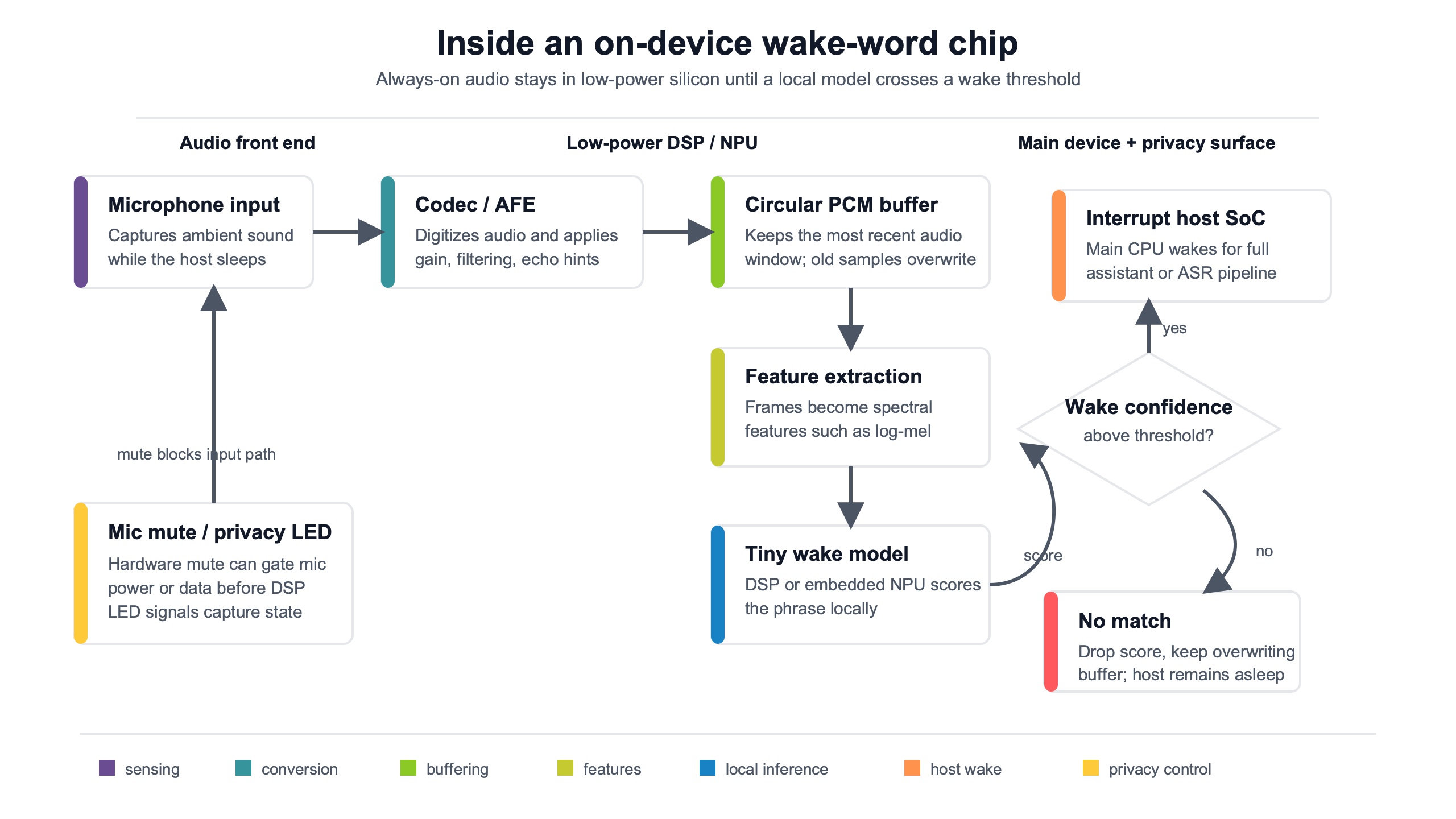
The pipeline shown here is the cleanest way to audit on device wake word chips: follow the audio from the microphone, through the buffer and feature extractor, into the model, then out through the host interrupt. The privacy question is not answered at the model box. It is answered by every storage and wake transition before and after that box.
A PDM microphone does not produce a finished voice command. It produces a high-rate digital bitstream that the audio front end decimates into PCM audio. That audio can then be processed locally, usually in short frames. A wake engine rarely runs on raw waveforms for every decision; it commonly converts audio to spectral features that are cheaper for a compact model to score.
The DMA ring buffer is the part many marketing pages skip. Direct memory access lets an audio peripheral fill memory without keeping the full host CPU awake. In a tiny always-on subsystem, that buffer may sit in SRAM attached to the DSP, audio codec, MCU, or NPU. In a larger system, it may sit in a low-power island that can wake the application processor only after a match.
Feature extraction is the second boundary. MFCCs and log-mel features are not pleasant to listen to like PCM audio, but they are still derived from speech. If a device stores features for debugging, model improvement, or wake analysis, that can still reveal speech patterns or speaker traits. On-device inference reduces cloud exposure, but it does not erase the need for data handling rules inside the device.
The keyword model produces a confidence score. A simple design sets a threshold: above it, wake; below it, keep listening. Better products add noise estimates, debounce logic, speaker direction, echo cancellation, and suppression for TV audio. That is why a wake phrase from one meter away in a quiet kitchen behaves differently from the same phrase under music, running water, or a television ad.
The host interrupt is the moment the gadget becomes visibly active. It may wake an application CPU, light an LED, start a voice session, open a network socket, or switch from a low-power buffer to a full command recorder. In a trustworthy design, these events are ordered and testable: the indicator changes when capture state changes, and the radio does not send audio before activation.
Why the rolling buffer is the hidden privacy boundary
The rolling buffer exists so the assistant does not clip the first word of a command after the wake phrase. It may hold recent PCM audio or compact features for a short time. That buffer is useful, but it is also the hidden privacy boundary because local inference can still involve temporary storage before the user sees any active recording signal.
Consider the ordinary kitchen command, “Alexa, turn off the oven light.” If the device waits until after the wake model fires before recording, it may miss “turn” because the host takes time to wake. A short pre-roll buffer fixes that by preserving audio from just before the activation point. The same mechanism can make a device feel fast and natural in a pair of earbuds or smart glasses.
The privacy cost is not that every buffer is dangerous. The cost is that buffer location, duration, and access control matter. A one-second SRAM ring buffer inside a power-island DSP that is overwritten constantly is a different risk from a longer PCM buffer exposed to application firmware. A feature buffer used only for scoring is different from raw audio retained for logs.
This is where vague “continuous listening without streaming” claims fall short. Continuous microphone sampling, local feature extraction, local keyword inference, rolling audio retention, host command capture, and cloud handoff are separate states. A product can be good on one and weak on another.
A practical buffer experiment is simple enough for a reviewer to describe without special lab gear. Speak the wake phrase, then leave 200 ms, 700 ms, and 1500 ms before the command. If the assistant preserves the start of the command after a very short gap, it probably uses pre-roll or aggressive host wake. If the first word is clipped at short gaps, the buffer may be short, disabled, or poorly integrated. This does not prove misuse, but it shows why the buffer exists.
For AI-enabled Cameras & Vision News readers, the same logic applies to devices that combine audio wake with visual wake. A doorbell or security camera may use a local audio trigger to wake a larger vision model. If the LED only turns on after cloud analysis starts, the user-visible signal trails the actual capture path.
| Stage | What exists there | Where it may live | Question to ask |
|---|---|---|---|
| Microphone sampling | PDM or PCM audio | Mic, codec, audio front end | Can a physical mute remove mic power? |
| Ring buffer | Recent audio or frames | DSP SRAM, MCU SRAM, shared memory | How many milliseconds are kept, and can the host read it? |
| Feature extraction | MFCC or log-mel features | DSP, MCU, NPU input memory | Are features retained for logs or erased after scoring? |
| Keyword scoring | Confidence values | MCU, DSP, NPU, local server | What threshold behavior is used in noise? |
| Host wake | Interrupt and session state | Application CPU, OS, assistant service | Does networking start before or after this point? |
| Command capture | Full speech command | Device, phone, hub, or cloud service | Is command recognition local, cloud-based, or mixed? |
DSP, MCU, NPU, or server: the architecture choice that decides battery life
The compute location decides how often the host wakes, how large the memory budget can be, how much latency users feel, and whether a radio is required before activation. MCU wake detection, DSP or codec wake detection, dedicated NPU chips, and server-side wake detection can all be “local” in casual language, but they are not equal designs.
Evaluation basis: This comparison treats wake-word design as an architecture check, not a lab benchmark. The source set was official vendor and project documentation available through May 10, 2026, including Sensory’s embedded wake-word material, Syntiant’s NDP material, Home Assistant voice documentation, openWakeWord, and microWakeWord. The key comparison points are compute location, buffer location, host wake behavior, radio dependency, and the privacy caveat. Power figures should be read as vendor-reported component claims unless a full-system measurement is specified.

The block breakdown matters because battery drain is spread across pieces: microphone bias, decimation, memory, feature extraction, model scoring, host wake, and radio use. A single “microwatt” headline for the inference chip can be accurate for that component while still failing to describe the full smart speaker, wearable, or smart home sensor.
| Design | Example source or product class | Compute location | Likely buffer location | Host wake behavior | Radio dependency | Privacy caveat |
|---|---|---|---|---|---|---|
| MCU wake detection | microWakeWord on ESP32-S3-class voice satellites | Microcontroller | MCU RAM | Host may be the same chip or a nearby hub | Not required for detection; may be needed for assistant response | Local trigger can still send the command to a server or cloud assistant after wake |
| DSP or audio-codec wake | Smartphones, earbuds, smart speakers, remotes | Low-power audio DSP or codec | DSP SRAM or audio subsystem memory | Application processor wakes after match | Not required for wake detection | Pre-roll audio may be passed to host when the session starts |
| Dedicated NPU wake chip | Syntiant NDP100/NDP101-class parts | Neural decision processor | NPU or attached low-power memory | Interrupt wakes larger system | Not required for keyword scoring | Component power is not full-device power; command handling may still be remote |
| Embedded vendor wake engine | Sensory TrulyHandsfree-style integrations | MCU, DSP, or other embedded target | Target platform memory | Depends on integration | Not required for wake phrase | Small RAM claims do not define buffer retention or LED behavior |
| Server-side local wake | Home Assistant openWakeWord on a local server | LAN server, hub, or single-board computer | Satellite stream buffer plus server memory | Satellite may stream audio to local server before wake | Requires local network path to the wake server | Private from cloud before wake, but not fully on-device at the microphone |
| Cloud wake detection | Older or thin-client voice products | Remote service | Device and cloud pipeline | Host and radio stay involved | Required for detection | Weakest fit for privacy-sensitive rooms and battery products |
For a battery door sensor with a tiny microphone, MCU or NPU wake detection is attractive because the radio can sleep until the phrase or acoustic event occurs. For a plugged-in smart display, the energy pressure is lower, but false wakes and privacy signals matter more because the device sits in a shared room. For earbuds, the tradeoff is severe: the wake engine must share a very small battery with Bluetooth audio, noise cancellation, and microphones.
Home Assistant’s split is useful because it uses clear names. The Home Assistant wake-word documentation points users toward creating wake words for its voice system, while the openWakeWord and microWakeWord projects show two different local paths: one where wake detection can run on a local server, and one where models target small devices such as ESP32-S3 voice hardware.
For Smart Glasses News and Wearables News, the practical rule is strict: if a product promises all-day battery life and a wake word, ask whether wake scoring runs on an always-on island or whether the main SoC must wake often. The first can be plausible. The second usually needs aggressive duty cycling, push-to-talk, or a bigger battery.
Privacy LEDs and mute switches: the trust signal has to follow the hardware state
A privacy LED is only as trustworthy as the signal that drives it. The strongest design ties the indicator or mute state to microphone power, capture hardware, or a protected firmware path. A weaker design lets an app decide when to show the LED, which can lag behind real audio capture or fail during a software fault.
There are three practical classes. A hardware-tied indicator follows microphone power, sensor enable, or capture clock state. A firmware-controlled indicator follows lower-level device firmware that is harder for ordinary apps to bypass. An app-controlled indicator follows user-interface state. The last class may still be useful, but it is a status message, not proof of capture state.
Physical mute switches deserve the same treatment. On a strong design, mute removes microphone bias power or opens a hardware gate so audio cannot be sampled. On a weaker design, mute sets a software flag that the voice service is supposed to honor. Apple’s platform-level microphone and camera indicators, described in Apple’s iPhone status icons and privacy indicator documentation, are a useful consumer reference point: they tell users when apps access sensors, but they are still part of a platform trust model rather than a teardown-level proof for every external device.
Smart speakers and displays often add visible LEDs because they do not have a personal screen. Amazon’s Echo devices, for example, use light rings and bars to signal states including listening and muted modes, described in Amazon’s Echo light indicator help. Those indicators are useful for users, but reviewers should still ask what event drives them: wake detection, command recording, cloud session, or a UI state.
The strict test is timing. If the LED turns on only after the spoken command has already begun, the pre-roll buffer may contain audio before the visible signal. That may be a reasonable engineering choice, but it should be disclosed plainly. If the LED remains off while a packet capture shows audio leaving the device, the indicator is not a reliable privacy signal.
How to read power claims without being misled
Power claims for on device wake word chips must be broken into components: microphone bias, audio conversion, memory, feature extraction, model inference, host wakeups, and radio activity. A tiny NPU number can be true and still not describe the battery life a user gets from the finished gadget.
Syntiant’s NDP100 and NDP101-class parts drew attention because they put neural wake-word scoring into a dedicated low-power component rather than the main application processor. Read that kind of claim at the component level. It does not automatically include the microphones, power management losses, memory outside the chip, application processor wake time, acoustic echo cancellation, Wi-Fi association, or the cloud assistant transaction after wake.
Sensory’s small-memory wake-word claims should be read the same way. A compact model is valuable because it can run in constrained hardware, but model memory is not the same as total audio memory. The system may still need frame buffers, feature buffers, pre-roll buffers, firmware, and integration code. For tiny AI Edge Devices News products, those extras can decide whether a design fits at all.
False wakes are also a power issue. A wake chip that uses very little energy while idle can waste far more energy if it wakes the host repeatedly because the TV says something similar to the wake phrase. Every false wake can start LEDs, radios, app processors, and assistant sessions. The wake engine’s job is not just low idle current; it is low total energy across a normal day in a noisy home.
Missed wakes create the opposite problem. If the threshold is too strict, users repeat the phrase, move closer, or disable the feature. If the threshold is too loose, the device wakes during TV speech and conversations. Certification programs for commercial assistants exist partly because vendors need repeatable behavior across noise, accents, distances, and microphone layouts. A product page that gives only a power number is leaving out the user experience.
The comparison view should be read from left to right: where compute happens, where audio waits, when the host wakes, and when the network becomes involved. If any column is unknown, “on-device” is still an incomplete claim. That missing column is where privacy or battery surprises usually appear.
For reviewers, the cleanest normalization is per event. Idle power matters for wearables and battery sensors. Wake latency matters for smart speakers and glasses. False wakes matter for every home device near TV audio. Network activity matters for privacy-sensitive rooms. Command accuracy matters after activation, but it should not be confused with wake-word accuracy.
A reviewer checklist for real devices
A real review should test the wake pipeline as a state machine: idle sampling, wake scoring, LED timing, host wake, command capture, and network behavior. The goal is not to reverse-engineer every chip. The goal is to verify whether the device’s visible behavior matches its privacy and battery claims.
Use a quiet room first, then a room with TV speech at conversational volume. Try the wake phrase at one meter and four meters. Record whether the device wakes, misses, or falsely wakes. Note whether the LED appears before the command, during the command, or only after a server response begins. Repeat the same test with the mute switch on, and confirm that the device does not react.
A packet capture can answer the most important network question: does traffic begin before the wake phrase, during the wake phrase, or only after the wake event? For a consumer-facing review, the result can be reported as a timestamped table rather than a technical trace. A local assistant may still show local network traffic before wake if it streams to a home server for openWakeWord. That is different from cloud streaming, but it is not the same as inference on the microphone device.
The buffer timing test is equally revealing. Speak the wake phrase, pause for 200 ms, then say a command. Repeat at 700 ms and 1500 ms. If short gaps preserve the command start, the device is probably using pre-roll or fast host capture. If only longer gaps work, the user experience may feel clumsy, but less pre-roll may be involved. Neither result is automatically good or bad; the point is to make the tradeoff visible.
- For battery wearables: prefer a dedicated low-power island, DSP, or NPU wake path, and treat frequent false wakes as a battery defect.
- For smart speakers and displays: inspect LED timing, mute behavior, and whether the command goes local or cloud after wake.
- For home security devices: require a clear capture indicator and a mute or disable mode that changes hardware state where possible.
- For local-first smart homes: distinguish on-device microWakeWord from LAN-server openWakeWord; both can avoid cloud wake detection, but they expose audio to different machines.
- For kids’ rooms and bedrooms: avoid products that cannot explain buffer retention, LED timing, and cloud handoff in plain documentation.
The decision framework is direct. Choose MCU wake detection when cost and small-device integration matter and the phrase set is limited. Choose DSP or codec wake detection when the product already has an audio subsystem and must keep the main SoC asleep. Choose a dedicated NPU when always-on neural scoring is core to the product and host wakeups must be rare. Choose server-side local wake only when the user accepts that audio may travel across the local network before activation. Avoid cloud wake detection for battery products and privacy-sensitive rooms unless there is a clear reason and a visible user control.
The phrase “on device wake word chips” should push buyers toward better questions, not automatic trust. Ask where the rolling buffer sits, what processor scores the wake phrase, what wakes the host, whether networking starts before activation, and whether the LED follows capture hardware. A local keyword model is a good start. The full chain decides whether the device behaves like a respectful appliance or just a smaller always-on microphone.
References
- Sensory TrulyHandsfree embedded wake-word technology
- Syntiant Neural Decision Processor technology
- openWakeWord GitHub repository
- microWakeWord GitHub repository
- Home Assistant wake-word documentation
- Espressif ESP32-S3-BOX documentation
- Apple microphone and camera privacy indicators
- Amazon Echo light indicator meanings