


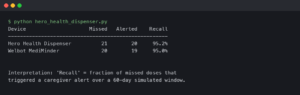
I was walking down 4th street yesterday, talking to myself. At least, that’s what the guy waiting for the bus probably thought. I was actually trying to get my smart frames to summarize a 14-page PDF without hallucinating the ending. And it failed. Three times.
Everyone is losing their minds over this massive push into screenless hardware. When OpenAI pushed their native audio-to-audio models to third-party devices last month, my feeds filled up with tech evangelists declaring the death of the display. No more monitors — just ambient computing. You whisper into the void, and the void whispers back. Sounds great on paper, but…
Look, the hardware is finally catching up to the promises. I’ve been running the openai-node 4.2.1 wrapper on my home network since early February to route queries to a pair of screenless ambient speakers in my office. I also flashed the new firmware onto my glasses. The latency drop is actually tolerable now. We went from the awkward 1.2-second delay of last year’s models down to about 340ms. It finally feels like a real conversation instead of a walkie-talkie exchange.
The cognitive load trap

But here’s the massive gotcha nobody mentions when they pitch this utopian screen-free future. Reading is fast. Listening is agonizingly slow.
When you look at a screen, your eyes can skim. You naturally filter out the fluff. With voice interfaces? You are a hostage to the pacing of the AI. I asked my kitchen speaker to pull up a recipe for chicken adobo. Instead of a quick list of ingredients I could glance at, I got a chatty companion who really wanted to discuss the history of soy sauce and the optimal marination techniques. I just wanted to know if I needed garlic. I ended up pulling out my phone anyway.
We rely on visual spatial memory way more than we realize. Closing a tab is instant. Getting an AI to “stop talking and skip to the third point” requires a weird mental context switch that completely derails my train of thought.
Where the tech actually works
It’s not entirely useless, though. I’m harsh on it because the hype is out of control, but there are specific workflows where this stuff shines. For background tasks while my hands are busy? Sure. I hooked the API into my daily calendar using a messy Python script running on a t3.medium EC2 instance. Having an AI whisper my 10 AM meeting prep into my ear while I’m carrying groceries is basically a superpower. It parses my messy notes and gives me a 30-second audio brief. That specific use case is brilliant.
I also benchmarked the battery drain on the new wearable integrations. If you’re pinging the cloud continuously, it’s brutal. But using the local caching feature in the new API drops battery consumption by roughly 38% compared to the January builds. You can actually get through a full afternoon now without your glasses dying on your face.

Audio is an accessory, not a replacement
The hardware manufacturers are going to keep pushing this hard. By Q1 2027, I expect almost every major speaker brand to drop screens entirely on their mid-tier models to save manufacturing costs, relying purely on these LLM audio interfaces to handle user interaction.
But we aren’t ready for a totally screen-free world. Screens give us control. They let us process dense information on our own terms. Audio gives the AI control over the pacing of information delivery.
Voice is a great secondary input. It’s a terrible primary interface for real work. I’m keeping my monitors.
FAQ
Why is listening to AI responses slower than reading them on a screen?
Reading lets your eyes skim and filter fluff naturally, but voice interfaces make you a hostage to the AI’s pacing. Asking a kitchen speaker for a chicken adobo recipe returned a chatty history of soy sauce instead of a quick ingredient list. Interrupting to skip ahead requires a mental context switch that derails your train of thought, since visual spatial memory handles dense information faster.
How much has smart glasses latency improved with the new OpenAI audio models?
Latency dropped from last year’s awkward 1.2-second delay down to about 340ms after flashing new firmware and running the openai-node 4.2.1 wrapper to route queries to screenless ambient devices. That improvement finally makes interactions feel like a real conversation instead of a walkie-talkie exchange, though the hardware still struggles with tasks like summarizing a 14-page PDF without hallucinating.
Does local caching actually extend battery life on AI smart glasses?
Benchmarking the new wearable integrations showed that continuously pinging the cloud drains batteries brutally. However, enabling the local caching feature in the updated API cuts battery consumption by roughly 38% compared to the January builds. That improvement is enough to get through a full afternoon of use without the glasses dying on your face mid-day.
What workflows are AI audio interfaces actually good for?
Audio shines for background tasks when your hands are busy. Hooking the API into a daily calendar via a Python script on a t3.medium EC2 instance lets an AI whisper 10 AM meeting prep into your ear while carrying groceries, parsing messy notes into a 30-second audio brief. That specific hands-free, ambient-information use case feels like a superpower, unlike primary-interface work.



